Using CodeVROOM with Local Models
This tutorial shows how to use CodeVROOM to edit your code with LLMs running on your own hardware. Running models locally is slower than using cloud, but it avoids sharing sensitive outside of your company, and can still prove useful with many routine tasks. In this tutorial we will show how to add a small focused edit to a large C file using the devstral model running on a Macbook Pro M3.
- Install Ollama on the machine where you would like to run it and run “ollama pull <model name>”. In this tutorial we will pull the gemma and devstral models:
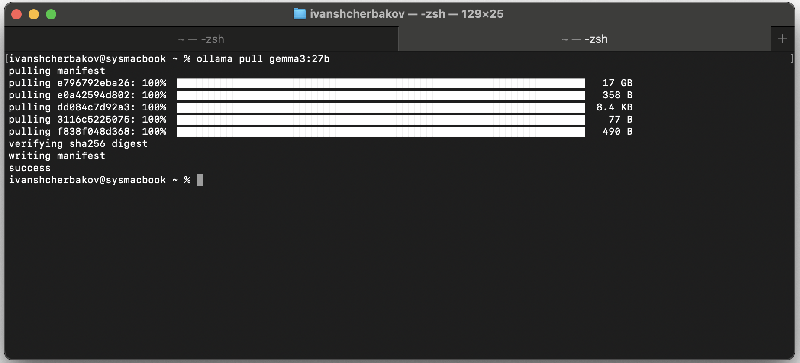
- Run”ollama serve” in the terminal so that it begins serving requests over HTTP:
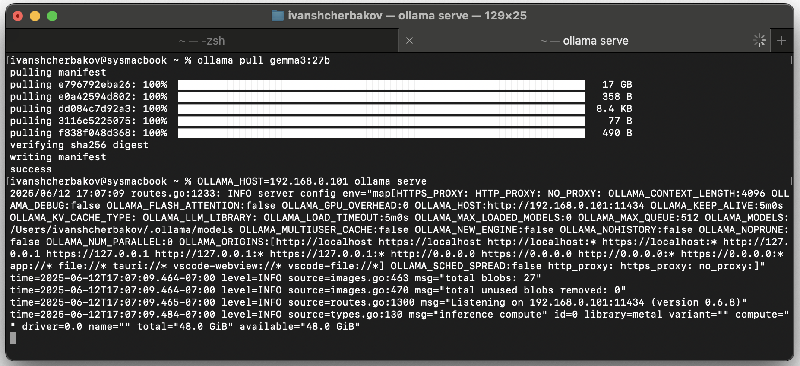 Note that by default, Ollama will bind to 127.0.0.1, and will only accept connections from the same machine. If you want to run Ollama and CodeVROOM on different machines, prepend “OLLAMA_HOST=<IP address of the host machine>” to the ollama command line, so that it binds to that interface.
Note that by default, Ollama will bind to 127.0.0.1, and will only accept connections from the same machine. If you want to run Ollama and CodeVROOM on different machines, prepend “OLLAMA_HOST=<IP address of the host machine>” to the ollama command line, so that it binds to that interface. - Download CodeVROOM and either install it or run it without installation. Then select AI->Manage AI Models:
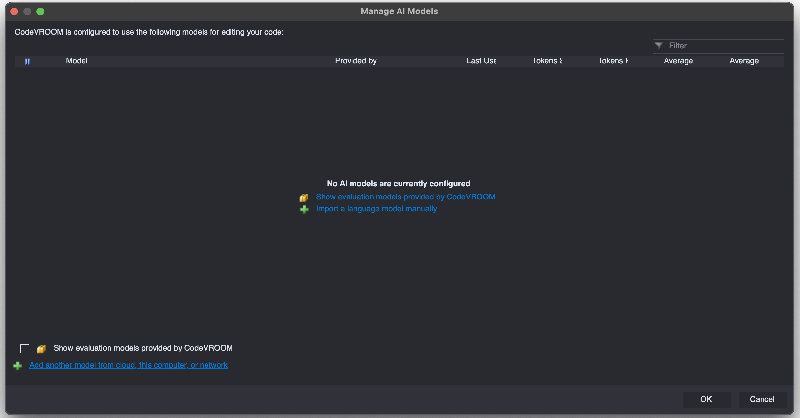
- If this is the first time you are running CodeVROOM, the model list will be empty. Click “Import a language model manually” to import one:
- Select “Run Ollama on this computer”:
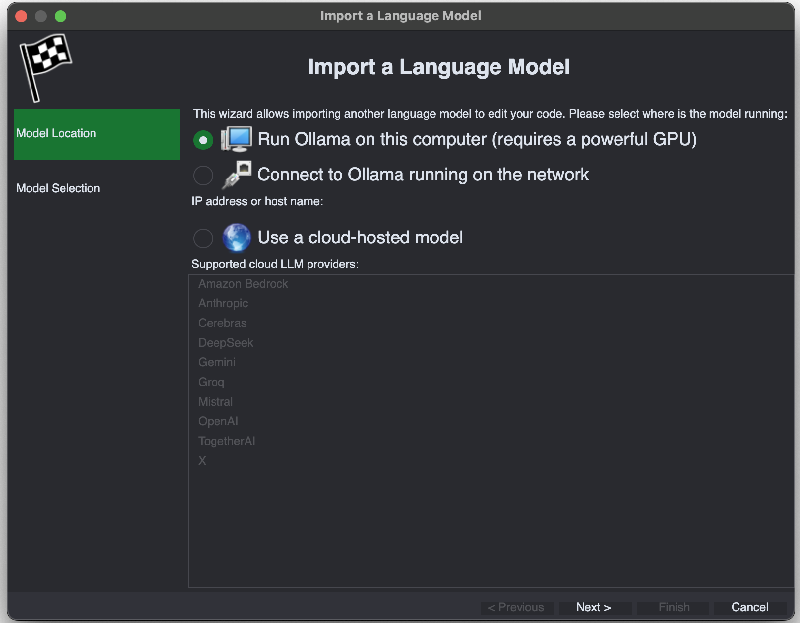
- On the next page select the models you want to import and click “Finish”:
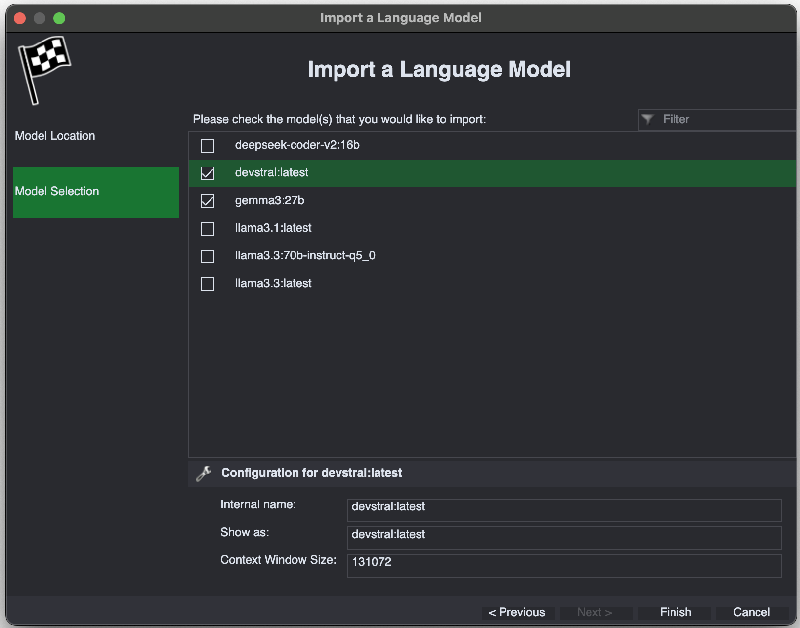
- The models will now appear in the model list:
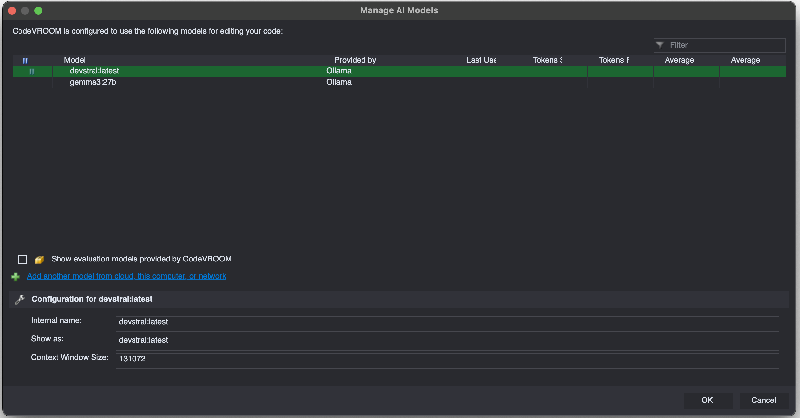
- We will now use the devstral model to add a small change to the Raspberry Pi Pico HTTP server project. Download the source code for it and open the folder via File->Open->Folder:
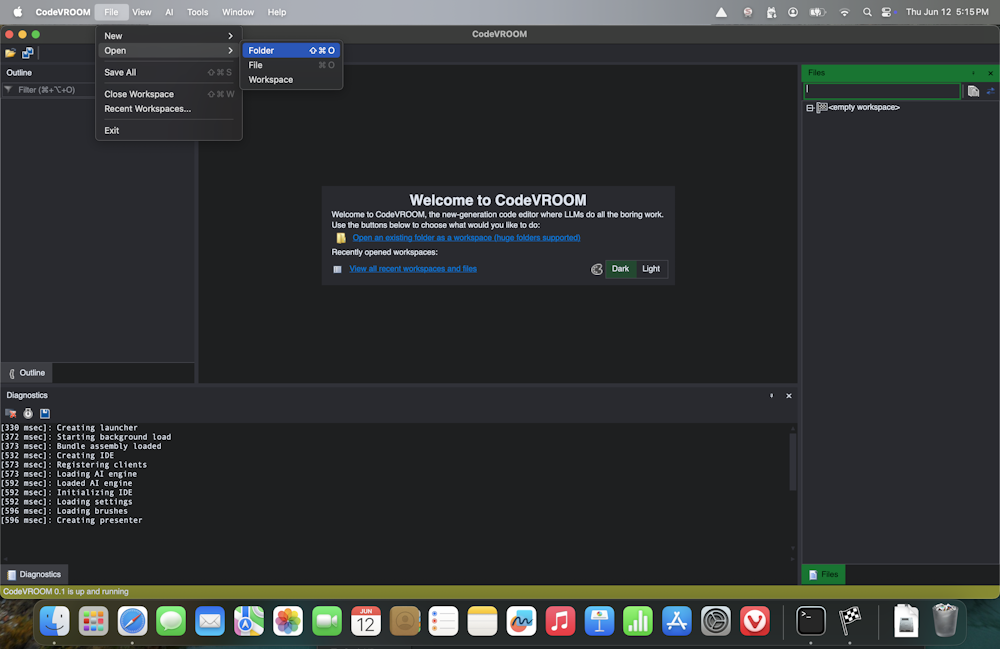
- Go to the main.c file:
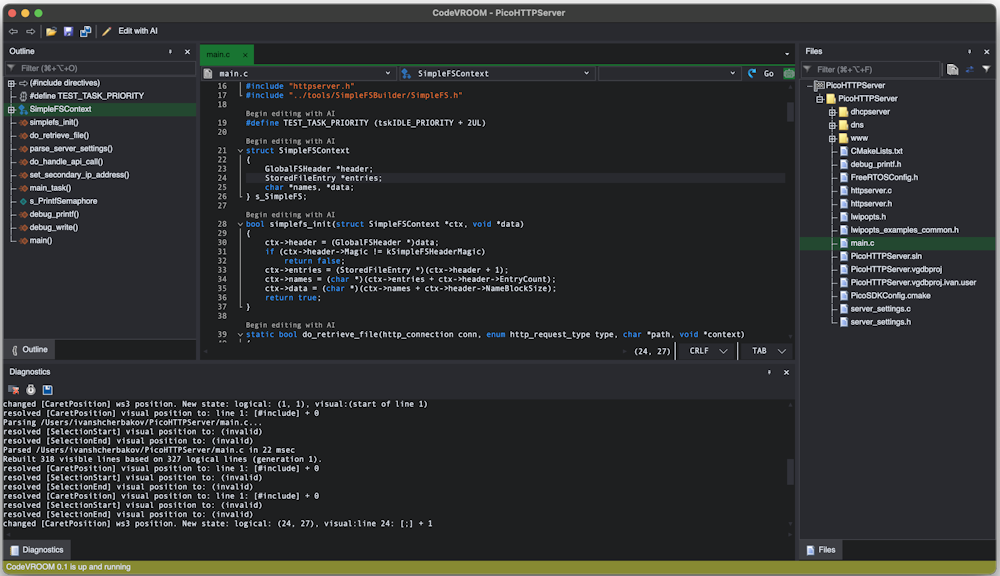 Note that the file itself is relatively large, so passing the entire file to the model could take some time to process. Instead, we will direct CodeVROOM to only include a few relevant bits in the context window.
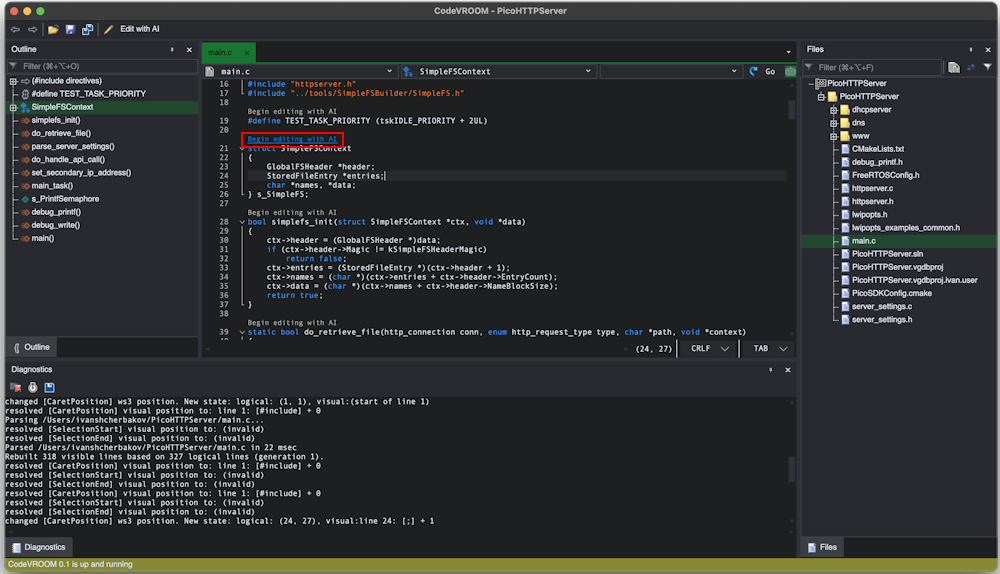
Note that the file itself is relatively large, so passing the entire file to the model could take some time to process. Instead, we will direct CodeVROOM to only include a few relevant bits in the context window. - Click the “Begin editing” link on top of the struct:
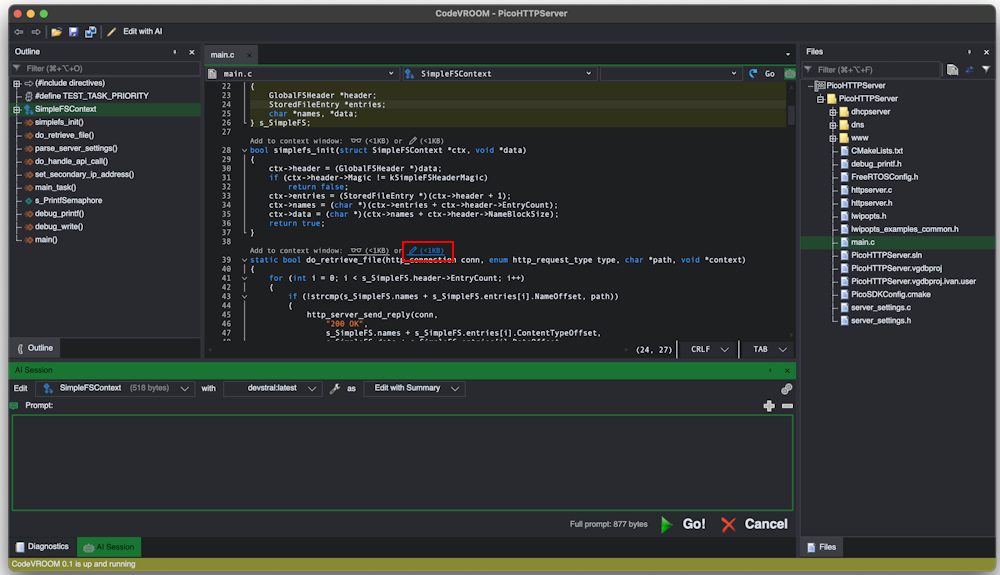
- Go to the do_retrieve_file() function and add it to the context window as an editable entity by clicking the “edit” button:
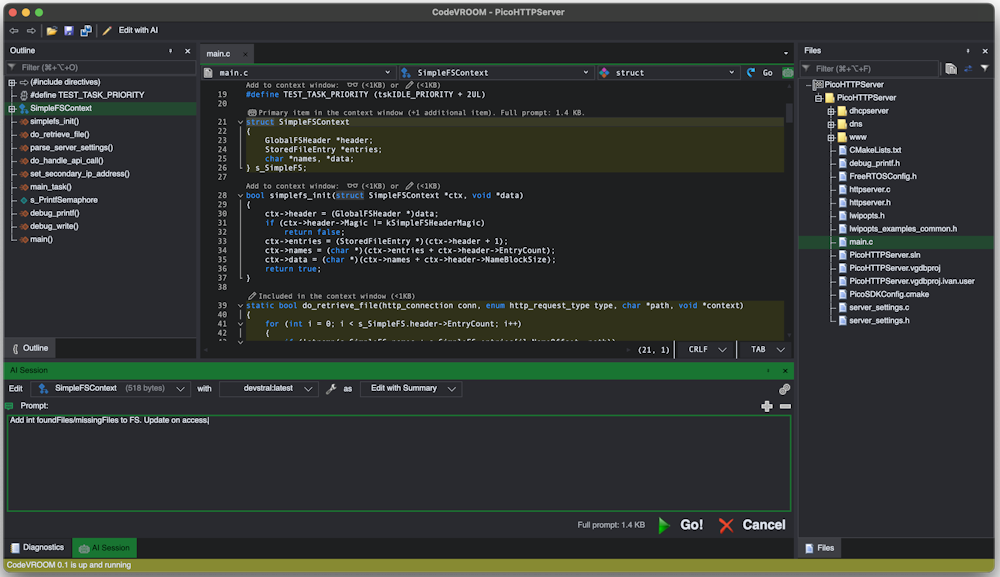
- Now that both struct and function are included in the context, you can add brief instructions what to do:
- CodeVROOM will show the tokens produced by the model in real time:
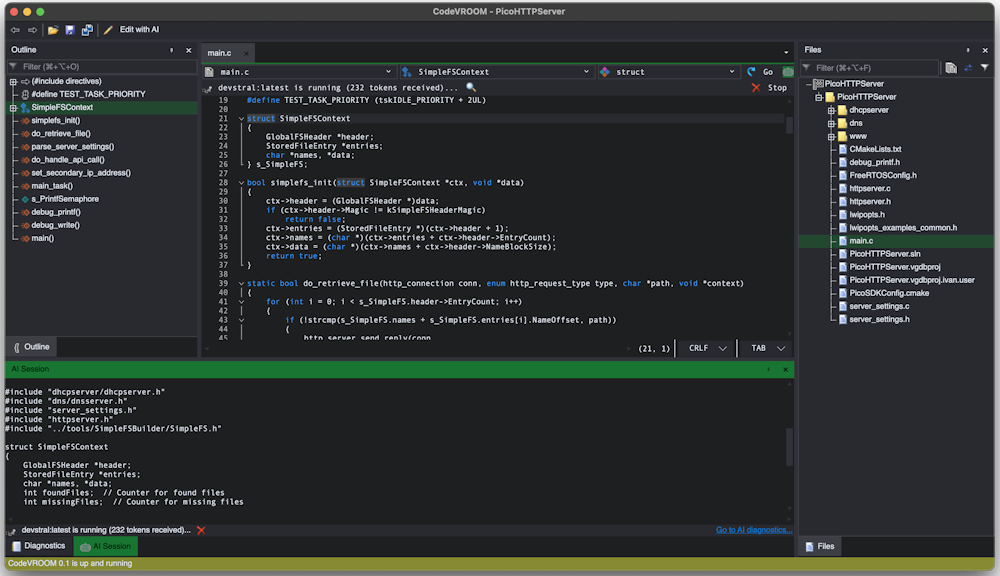 If you see that the model has taken a wrong turn, you can cancel the request, go back, tweak the prompt and re-run it.
If you see that the model has taken a wrong turn, you can cancel the request, go back, tweak the prompt and re-run it. - Once the model finishes the output, CodeVROOM will automatically match it against your file and highlight the differences:
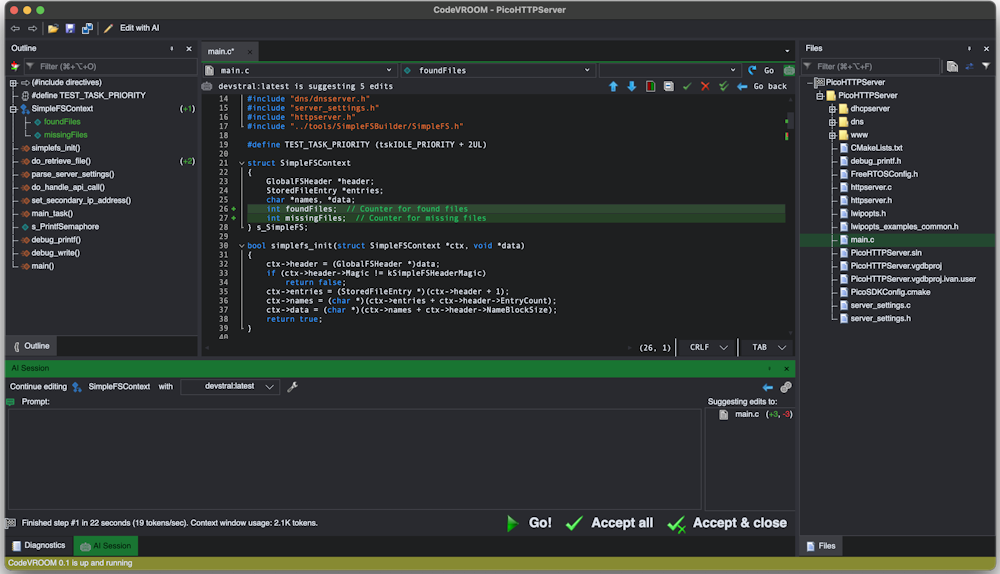
- You can approve or reject each individual edit, or approve them all at once. Use the filter buttons to temporarily collapse unchanged parts of the code:
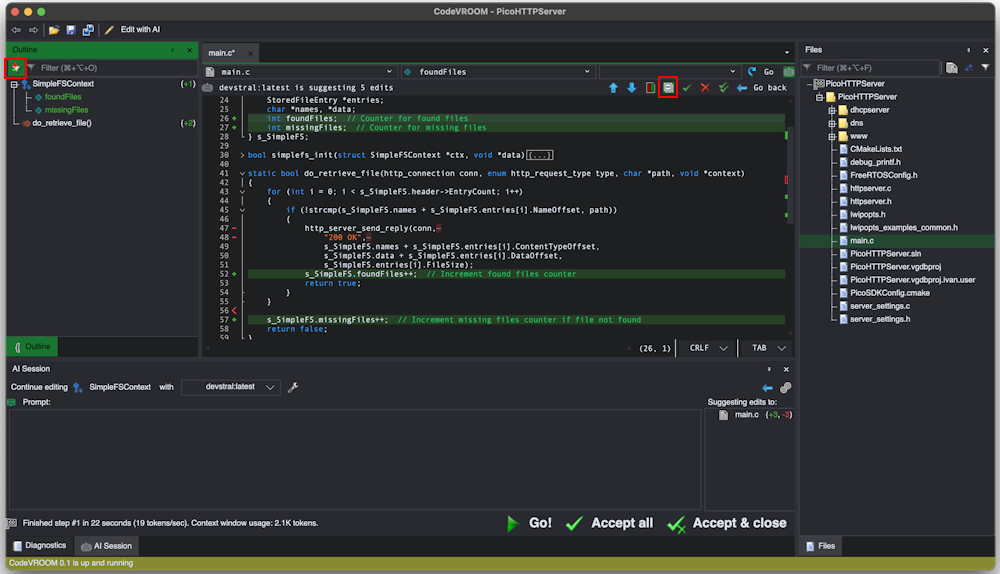
- You can try different models with different sizes to find the optimal trade-off between output quality and speed:
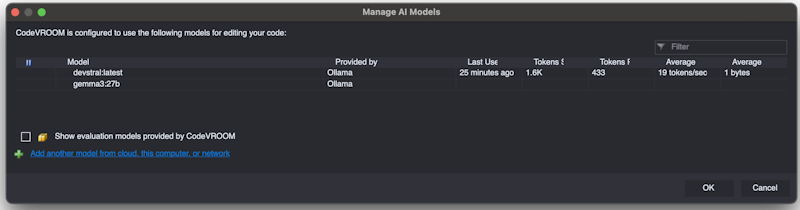 The AI Manager window will show the average bytes per token and tokens per second for each model, so you can compare them more easily.
The AI Manager window will show the average bytes per token and tokens per second for each model, so you can compare them more easily.
Small models are somewhat more sensitive to the phrasing of the prompt. You can tweak how exactly CodeVROOM builds prompts from the code snippets and your requests by editing the files in the PromptTemplates folder. Note that asking a model to give a summary of changes before writing any code often improves the quality of the output.