Symbol-Level Editing
CodeVROOM uses symbol-level editing to significantly reduce the amount of source code that the language model has to deal with. This page explains how it works and why it provides better results.
The Problem
Language models have a limited context window. It limits the amount of code you can “show” to the model at once before it forgets everything it was looking at. And, if you are having a longer conversation with the model, discussing several versions of the code, you want all of them to be able to fit.
The context windows typically vary from ~128K tokens (~500KB of text) for smaller models to a whopping 1M tokens (4-5MB of text) for larger models like Google Gemini 2.5 Pro. It can usually fit single files, but not entire projects.
When you start a chat using a conventional AI editor, it would usually attach the current file, and some other relevant files into the conversation, and let the model figure it out. When you use agentic tools, the model would proactively read files in your project into the context window, and decide when to stop. Both ways feed a lot of code into the context window, increasing the response time and building up the token costs.
The CodeVROOM Approach
CodeVROOM combines the best from the chat-based and agentic worlds. It splits every AI editing session into a context discovery phase and the actual editing phase. During the context discovery phase, the model looks at a small code snippet, and tells CodeVROOM which additional symbols are critical to the task. This process can be repeated several times, depending on your preferences.
Once the context discovery is complete, CodeVROOM starts a new conversation where it includes all previously discovered symbols, and asks the model to actually edit it per your original instructions.
If you are using a smaller model (e.g. Llama 3.3 running on the Cerebras platform), you can get many scattered edits done in one or two seconds. And if the small model gets confused, you can easily redo the same step with a larger model. Or use a smaller model for context discovery and a larger model for editing.
A Practical Example
Here’s a fairly simple WPF window from our VisualGDB product showing a list of sources for a particular CMake target: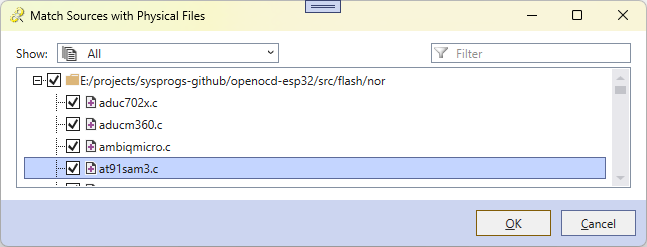 The window can show all files, currently checked files, unchecked files, or missing files only. It relies on an in-house WPF control for searchable trees. If you wanted to implement the filtering logic, you would need to come up with a body for the ApplyFilterToNode() method:
The window can show all files, currently checked files, unchecked files, or missing files only. It relies on an in-house WPF control for searchable trees. If you wanted to implement the filtering logic, you would need to come up with a body for the ApplyFilterToNode() method:
public enum NodeFilterMode
{
ShowAll,
CheckedOnly,
UncheckedOnly,
MissingOnly,
}
public class NodeTypeFilter : NotifyPropertyChangedImpl, IPresentableTreeFilter<NodeBase>
{
public bool ShowAllNodes => Mode == NodeFilterMode.ShowAll;
NodeFilterMode _Mode;
public NodeFilterMode Mode
{
get => _Mode;
set
{
_Mode = value;
OnPropertyChanged(nameof(Mode));
FilterChanged?.Invoke(this, EventArgs.Empty);
}
}
public event EventHandler FilterChanged;
public AdvancedNodeFilteringResult ApplyFilterToNode(NodeBase node)
{
}
}
The actual filtering logic is fairly trivial: you go through all possible values of Mode, and for each value, check the corresponding property of the node. If you were doing it by hand, you would look up the definition of:
- NodeBase and its public members
- AdvancedNodeFilteringResult to know what you are returning
- NodeFilterMode
You would also not care about the internals how exactly the Mode setter is implemented. Just knowing that it’s there would suffice:
public NodeFilterMode Mode { get; set; }
Different story with AI. Asking it in a regular chat would outright hallucinate AdvancedNodeFilteringResult because it’s defined elsewhere. Doing an agentic edit would work, but would take time and tokens, letting the model look through multiple files.
Symbol-level edits solve it efficiently and fast: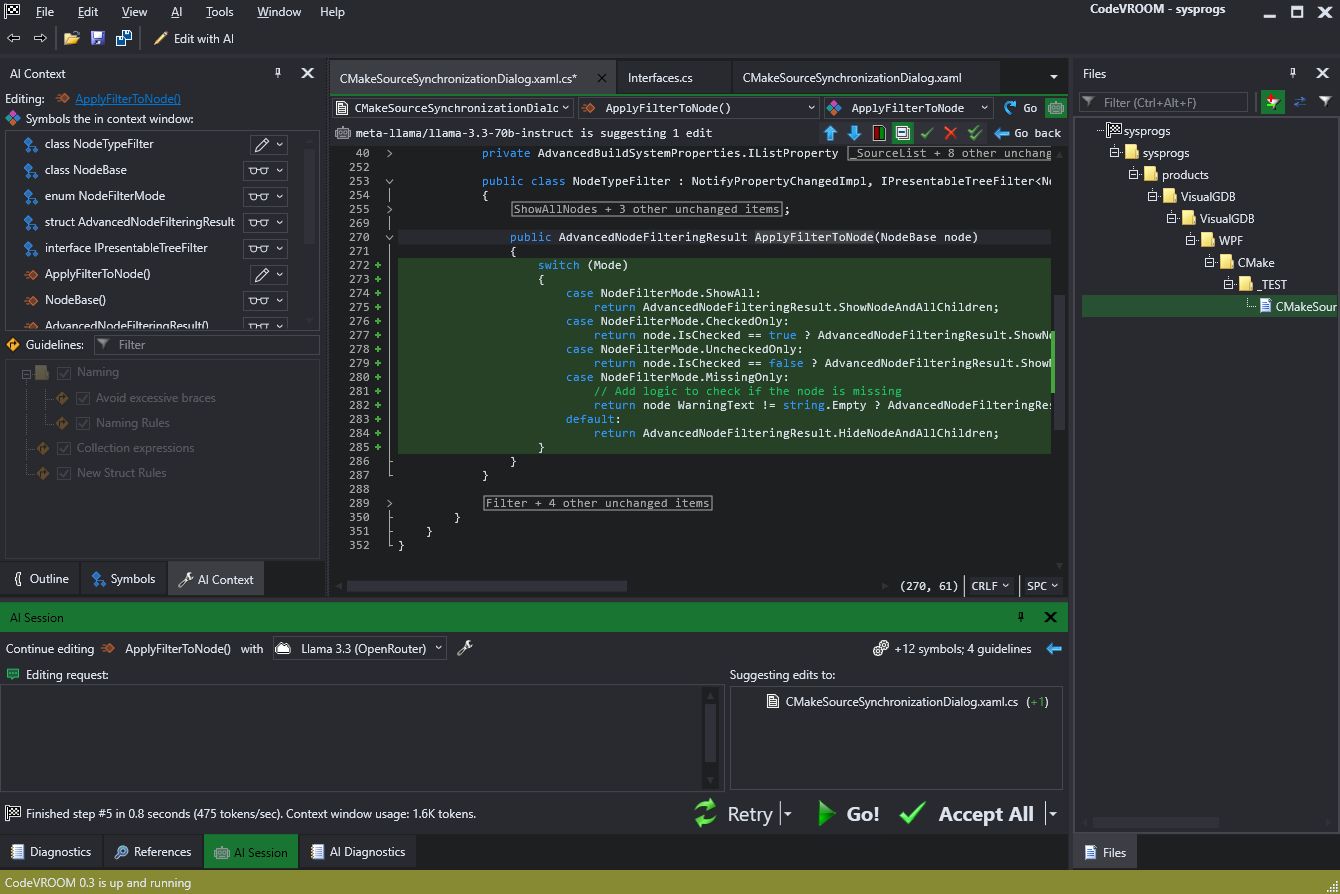 It took less than a second and a negligible amount of tokens to do the actual edit using the Cerebras platform. The model correctly figured out how to use AdvancedNodeFilteringResult, and what to check for each value of NodeFilterMode. It misspelled “node WarningText” instead of “node.WarningText” and didn’t use IsNullOrEmpty(), but that’s a an easy fix. It’s just way faster to type “implement” as a prompt and get a reviewable draft moments later, than to write everything by hand.
It took less than a second and a negligible amount of tokens to do the actual edit using the Cerebras platform. The model correctly figured out how to use AdvancedNodeFilteringResult, and what to check for each value of NodeFilterMode. It misspelled “node WarningText” instead of “node.WarningText” and didn’t use IsNullOrEmpty(), but that’s a an easy fix. It’s just way faster to type “implement” as a prompt and get a reviewable draft moments later, than to write everything by hand.